Configuration for Central Managers
Introduction
The Center Manager machine, or CM, is a role that usually runs on one machine in your pool. In some ways, it defines the extent and scope of the pool. A central manager must run at least one condor_collector and condor_negotiator daemon, and most pools run exactly one of each. Some large sites run multiple collectors, perhaps on multiple machines, to handle the load over a very large pool (say, more than 100,000 slots), or to move the load of handling monitoring and reporting queries to a different collector than is handling the operational aspects of running a pool, or to improve the availability of the pool as a whole. In the same way, most pools run with a single negotiator negotiator daemon, but in some specialized configurations, separate negotiators can handle fast matching to a subset of the pool, or break the pool accounting into separate shards.
The condor_collector is mainly an in-memory datastore of classads representing all of the daemons and all of the slots in the pool. Because it keeps this in memory, all state of the pool’s daemons is lost when it restarts. To mitigate problems with restarts, each daemon is responsible to periodically send the current value of its classad to the collector, usually, no less frequently than every five minutes. Thus even after a restart, the whole state of the pool will refresh within five minutes. Most of the various options to the condor_status command query the condor_collector. There is not much configuration for the condor_collector daemon.
The condor_negotiator, is responsible for allocating the slots of the pools to users according to the policies of the administrators of the CM and the EP. Thus, there is a lot of configuration control that you have over this daemon and how it works. Scheduling of jobs is a two-phased process. The condor_negotiator tries to balance the allocation of all the slots in the pool in some fair way. It then give these allocated slots to the condor_schedd’s that hold the jobs of those users, and it is the condor_schedd on the AP that is responsible for the final selection of which jobs run on which slots. The condor_schedd can re-use a match the negotiator has given it to run multiple jobs in succession. Because of this, the negotiator isn’t as time-critical for starting jobs as the condor_schedd might be, so it can afford to take more time to make better decisions. The condor_negotiator has a pool-wide view of scheduling, but the condor_schedd can only see those slots in the pool that have been assigned to it.
Configuration and Operation of the Negotiator
The Negotiation Cycle
The heart of the condor_negotiator is the negotiation cycle. The condor_negotiator runs the negotiation cycle, a cpu-bound process which can run for minutes, then waits for NEGOTIATOR_CYCLE_DELAY before starting the next cycle. During this delay, the rest of the system processes the decisions made by the negotiator, and the negotiator can also respond to queries made by condor_userprio and other tools. The job of the negotiation cycle is to match slots to submitters and their jobs.
Build a list of all the slots, subject to NEGOTIATOR_SLOT_CONSTRAINT This is the equivalent of running condor_status. If NEGOTIATOR_CONSIDER_PREEMPTION is false, only use idle slots. This means preemption can’t happen, but negotiation will be much faster.
Obtain a list of all job submitters This is the equivalent of running condor_status -submitters.
Sort the list of all job submitters based on the Effective User Priority (EUP) (see below for an explanation of EUP). The submitter with the lowest numerical priority is first. The command condor_userprio shows the EUP for each submitter.
Calculate the “fair share” for each submitter, which is the number of cores each submitter should be getting, and the actual number of cores each submitter is using. Note that as some submitters may have less demand for slots than their fair share, these excess slots might be allocated to other submitters, putting them over their fair share.
Iterate until the negotiator runs out of slots or jobs.
For each submitter below their floor, if any; after those, for all submitters, both in EUP order:
Fetch an idle job from a condor_schedd holding jobs from that submitter. The condor_schedd will present the jobs to the negotiator in job priority order.
Build a potential match list of slots where this job could run, out of all the slots the negotiator fetched in the first step above:
Skip slots where
machine.requirementsevaluates toFalseorjob.requirementsevaluates toFalse. That is, skip the slot if it does not match the job’s requirements or vice-versa.Skip slots in the Claimed state, but not running a job.
For slots not running a job, add to the potential match list with a reason of No Preemption.
For slots running a job
If the
machine.RANKon this job is better than the running job, add the slot to the potential match list with a reason of Rank.If the EUP of this job is better than the EUP of the currently running job, and PREEMPTION_REQUIREMENTS is
True, and themachine.RANKon the job is not worse than the currently running job, add the slot to the potential match list with a reason of Priority. See example below.
Sort the potential match list, first by NEGOTIATOR_PRE_JOB_RANK. If two or more slots have the same value, sort those by
job.RANK. Break any more ties by sorting by NEGOTIATOR_POST_JOB_RANK. Further ties are broken by reason for claim (No Preemption, then Rank, then Priority), and finally PREEMPTION_RANK.The job is assigned to the top slot on the potential match list. The slot is then removed from the list of slots to match (on this negotiation cycle).
Ask the condor_schedd for the next idle job for this submitter. If there are no more idle jobs, move to the next submitter.
As described above, the condor_negotiator tries to match each job
to all slots in the pool. Assume that five slots match one request for
three jobs, and that their NEGOTIATOR_PRE_JOB_RANK, Job.Rank,
and NEGOTIATOR_POST_JOB_RANK expressions evaluate (in the context
of both the slot ad and the job ad) to the following values.
Slot Name |
NEGOTIATOR_PRE_JOB_RANK |
Job.Rank |
NEGOTIATOR_POST_JOB_RANK |
|---|---|---|---|
slot1 |
100 |
1 |
10 |
slot2 |
100 |
2 |
20 |
slot3 |
100 |
2 |
30 |
slot4 |
0 |
1 |
40 |
slot5 |
200 |
1 |
50 |
Table 3.1: Example of slots in the potential match list before sorting
These slots would be sorted first on NEGOTIATOR_PRE_JOB_RANK, then
sorting all ties based on Job.Rank and any remaining ties sorted by
NEGOTIATOR_POST_JOB_RANK. After that, the first three slots would be
handed to the condor_schedd. This means that
NEGOTIATOR_PRE_JOB_RANK is very strong, and overrides any ranking
expression by the submitter of the job. After sorting, the slots would look
like this, and the schedd would be given slot5, slot3 and slot2:
Slot Name |
NEGOTIATOR_PRE_JOB_RANK |
Job.Rank |
NEGOTIATOR_POST_JOB_RANK |
|---|---|---|---|
slot5 |
200 |
1 |
50 |
slot3 |
100 |
2 |
30 |
slot2 |
100 |
2 |
20 |
slot1 |
100 |
1 |
10 |
slot4 |
0 |
1 |
40 |
Table 3.2: Example of slots in the potential match list after sorting: Here, slot5 would be the first slot given to a submitter.
The condor_negotiator asks the condor_schedd for the “next job” from a given submitter/user. Typically, the condor_schedd returns jobs in the order of job priority. If priorities are the same, job submission time is used; older jobs go first. If a cluster has multiple procs in it and one of the jobs cannot be matched, the condor_schedd will not return any more jobs in that cluster on that negotiation pass. This is an optimization based on the theory that the cluster jobs are similar. The configuration variable NEGOTIATE_ALL_JOBS_IN_CLUSTER disables the cluster-skipping optimization. Use of the configuration variable SIGNIFICANT_ATTRIBUTES will change the definition of what the condor_schedd considers a cluster from the default definition of all jobs that share the same ClusterId.
User Priorities and Negotiation
HTCondor uses priorities to allocate slots to jobs. This section details the priorities and the allocation of slots (negotiation).
Note
A video describing how user priorities, negotiation and fair share work in HTCondor is available at https://www.youtube.com/watch?v=NNnrCjFV0tM
For accounting purposes, each user is identified by username@uid_domain. Each user is assigned a priority value even if submitting jobs from different Access Points in the same domain, or even if submitting from multiple machines in the different domains.
The numerical priority value assigned to a user is inversely related to the goodness of the priority. A user with a numerical priority of 5 gets more slots (or bigger slots) than a user with a numerical priority of 50. There are two priority values assigned to HTCondor users:
Real User Priority (RUP), which measures resource usage of the user.
Effective User Priority (EUP), which determines the number of slots the user can get.
This section describes these two priorities and how they affect resource allocations in HTCondor. Documentation on configuring and controlling priorities may be found in the Negotiator Daemon Configuration Options section.
Real User Priority (RUP)
A user’s RUP reports a smoothed average of the number of cores a user has used over some recent period of time. Every user begins with a RUP of one half (0.5), which is the lowest possible value. At steady state, the RUP of a user equilibrates to the number of cores currently used. So, if a specific user continuously uses exactly ten cores for a long period of time, the RUP of that user asymptotically approaches ten.
However, if the user decreases the number of cores used, the RUP asymptotically lowers to the new value. The rate at which the priority value decays can be set by the macro PRIORITY_HALFLIFE, a time period defined in seconds. Intuitively, if the PRIORITY_HALFLIFE in a pool is set to the default of 86400 seconds (one day), and a user with a RUP of 10 has no running jobs, that user’s RUP would be 5 one day later, 2.5 two days later, and so on.
For example, if a new user has no historical usage, their RUP will start at 0.5 If that user then has 100 cores running, their RUP will grow as the graph below show:
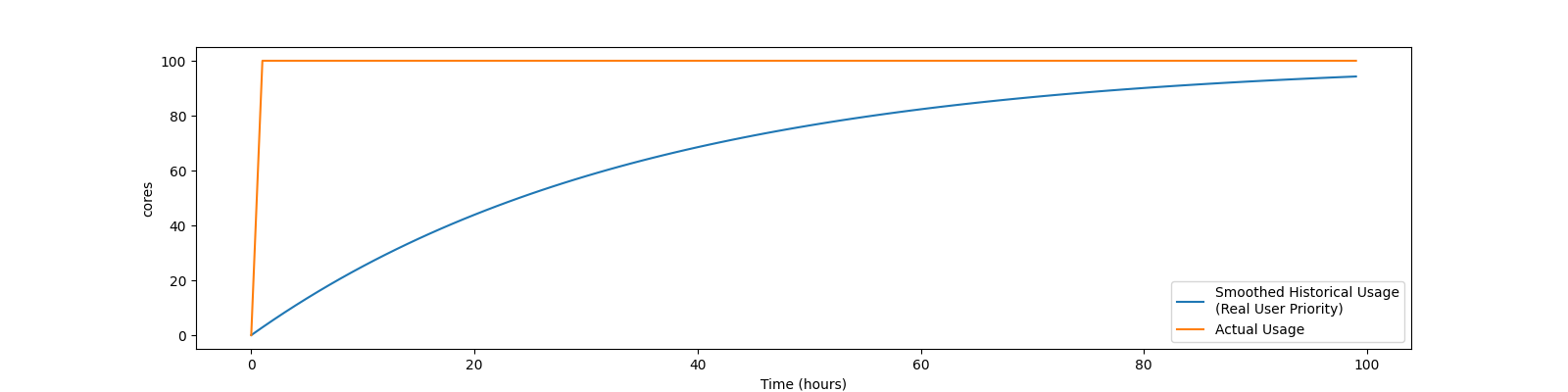
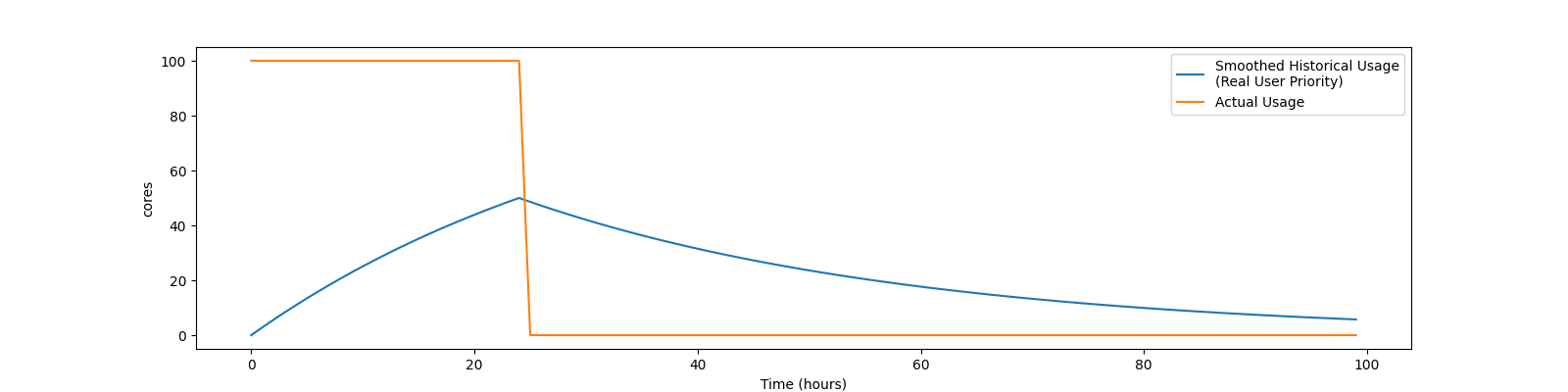
Or, if a new user with no historical usage has 100 cores running for 24 hours, then removes all the jobs, so has no cores running, their RUP will grow and shrink as shown below:
Effective User Priority (EUP)
The effective user priority (EUP) of a user is used to determine how many cores a user should receive. The EUP is simply the RUP multiplied by a priority factor the administrator can set per-user. The default initial priority factor for all new users as they first submit jobs is set by the configuration variable DEFAULT_PRIO_FACTOR, and defaults to 1000.0. An administrator can change this priority factor using the condor_userprio command. For example, setting the priority factor of some user to 2,000 will grant that user half as many cores as a user with the default priority factor of 1,000, assuming they both have the same historical usage, because their EUPs will differ by a factor of two.
The number of slots that a user may receive is inversely related to the ratio between the EUPs of submitting users. User A with EUP=5 will receive twice as many slots as user B with EUP=10 and four times as many slots as user C with EUP=20. However, if A does not use the full number of slots that A may be given, the available slots are repartitioned and distributed among remaining users according to the inverse ratio rule.
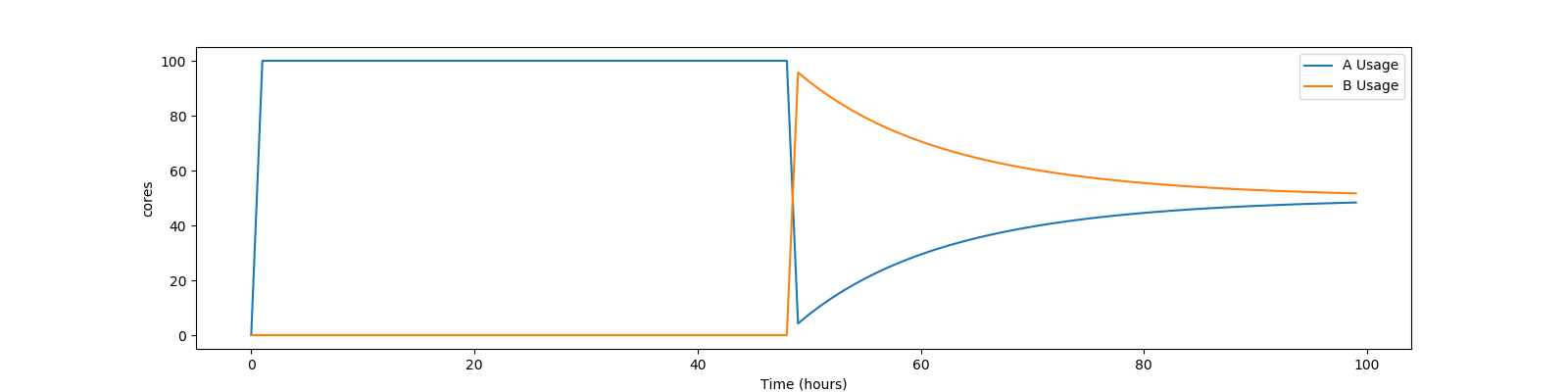
Assume two users with no history, named A and B, using a pool with 100 cores. To simplify the math, also assume both users have an equal priority factor of 1.0. User A submits a very large number of short-running jobs at time t = 0 zero. User B waits until 48 hours later, and also submits an infinite number of short jobs. At the beginning, the EUP doesn’t matter, as there is only one user with jobs, and so user A gets the whole pool. At the 48 hour mark, both users compete for the pool. Assuming the default PRIORITY_HALFLIFE of 24 hours, user A’s RUP should be about 75.0 at the 48 hour mark, and User B will still be the minimum of .5. At that instance, User B deserves 150 times User A. However, this ratio will decay quickly. User A’s share of the pool will drop from all 100 cores to less than one core immediately, but will quickly rebound to a handful of cores, and will asymptotically approach half of the pool as User B gets the inverse. A graph of these two users might look like this:
HTCondor supplies mechanisms to directly support two policies in which EUP may be useful:
- Nice users
A job may be submitted with the submit command nice_user set to
True. This nice user job will have its RUP boosted by the NICE_USER_PRIO_FACTOR priority factor specified in the configuration, leading to a very large EUP. This corresponds to a low priority for slots, therefore using slots not used by other HTCondor users.- Remote Users
HTCondor’s flocking feature (see the Connecting HTCondor Pools with Flocking section) allows jobs to run in a pool other than the local one. In addition, the submit-only feature allows a user to submit jobs to another pool. In such situations, submitters from other domains can submit to the local pool. It may be desirable to have HTCondor treat local users preferentially over these remote users. If configured, HTCondor will boost the RUPs of remote users by REMOTE_PRIO_FACTOR specified in the configuration, thereby lowering their priority for slots.
The priority boost factors for individual users can be set with the setfactor option of condor_userprio. Details may be found in the condor_userprio manual page.
Priorities in Negotiation and Preemption
Priorities are used to ensure that users get their fair share of slots in the pool. The priority values are used at allocation time, meaning during negotiation and matchmaking. Therefore, there are ClassAd attributes that take on defined values only during negotiation, making them ephemeral. In addition to allocation, HTCondor may preempt a slot claim and reallocate it when conditions change.
Too many preemptions lead to thrashing, a condition in which negotiation for a slot identifies a new job with a better priority most every cycle. Each job is, in turn, preempted, and no job finishes. To avoid this situation, the PREEMPTION_REQUIREMENTS configuration variable is defined for and used only by the condor_negotiator daemon to specify the conditions that must be met for a preemption to occur. When preemption is enabled, it is usually defined to deny preemption if a current running job has been running for a relatively short period of time. This effectively limits the number of preemptions per resource per time interval. Note that PREEMPTION_REQUIREMENTS only applies to preemptions due to user priority. It does not have any effect if the slot’s RANK expression prefers a different job, or if the slot’s policy causes the job to vacate due to other activity on the slot. See the condor_startd Policy Configuration section for the current default policy on preemption.
The following ephemeral attributes may be used within policy definitions. Care should be taken when using these attributes, due to their ephemeral nature; they are not always defined, so the usage of an expression to check if defined such as
(RemoteUserPrio =?= UNDEFINED)
is likely necessary.
Within these attributes, those with names that contain the string Submitter
refer to characteristics about the candidate job’s user; those with names that
contain the string Remote refer to characteristics about the user currently
using the resource. Further, those with names that end with the string
ResourcesInUse have values that may change within the time period
associated with a single negotiation cycle. Therefore, the configuration
variables PREEMPTION_REQUIREMENTS_STABLE and
PREEMPTION_RANK_STABLE exist to inform the condor_negotiator daemon
that values may change. See the
Negotiator Daemon Configuration Options section for definitions of these configuration variables.
-
SubmitterUserPrio A floating point value representing the user priority of the candidate job.
-
SubmitterUserResourcesInUse The integer number of slots currently utilized by the user submitting the candidate job.
-
RemoteUserPrio A floating point value representing the user priority of the job currently running on the slot. This version of the attribute, with no slot represented in the attribute name, refers to the current slot being evaluated.
-
Slot<N>_RemoteUserPrio A floating point value representing the user priority of the job currently running on the particular slot represented by <N> on the slot.
-
RemoteUserFloor An integer value representing the resource/slot floor (minimum number of slots guaranteed to the user) for the job currently running on the slot. This version of the attribute, with no slot represented in the attribute name, refers to the current slot being evaluated.
-
RemoteUserResourcesInUse The integer number of slots currently utilized by the user of the job currently running on the slot.
-
SubmitterGroupResourcesInUse If the owner of the candidate job is a member of a valid accounting group, with a defined group quota, then this attribute is the integer number of slots currently utilized by the group.
- SubmitterGroup
The accounting group name of the requesting submitter.
-
SubmitterGroupQuota If the owner of the candidate job is a member of a valid accounting group, with a defined group quota, then this attribute is the integer number of slots defined as the group’s quota.
-
RemoteGroupResourcesInUse If the owner of the currently running job is a member of a valid accounting group, with a defined group quota, then this attribute is the integer number of slots currently utilized by the group.
- RemoteGroup
The accounting group name of the owner of the currently running job.
-
RemoteGroupQuota If the owner of the currently running job is a member of a valid accounting group, with a defined group quota, then this attribute is the integer number of slots defined as the group’s quota.
- SubmitterNegotiatingGroup
The accounting group name that the candidate job is negotiating under.
- RemoteNegotiatingGroup
The accounting group name that the currently running job negotiated under.
- SubmitterAutoregroup
Boolean attribute is
Trueif candidate job is negotiated via autoregroup.- RemoteAutoregroup
Boolean attribute is
Trueif currently running job negotiated via autoregroup.
Priority Calculation
This section may be skipped if the reader so feels, but for the curious, here is HTCondor’s priority calculation algorithm.
The RUP of a user \(u\) at time \(t\), \(\pi_{r}(u,t)\), is calculated every time interval \(\delta t\) using the formula
where \(\rho (u,t)\) is the number of cores used by user \(u\) at time \(t\), and \(\beta = 0.5^{\delta t / h}\). \(h\) is the half life period set by PRIORITY_HALFLIFE.
The EUP of user \(u\) at time \(t\), \(\pi_{e}(u,t)\) is calculated by
where \(f(u,t)\) is the priority boost factor for user \(u\) at time \(t\).
As mentioned previously, the RUP calculation is designed so that at steady state, each user’s RUP stabilizes at the number of cores used by that user. The definition of \(\beta\) ensures that the calculation of \(\pi_{r}(u,t)\) can be calculated over non-uniform time intervals \(\delta t\) without affecting the calculation. The time interval \(\delta t\) varies due to events internal to the system, but HTCondor guarantees that unless the central manager is down, no matches will be unaccounted for due to this variance.
The Layperson’s Description of the Pie Spin and Pie Slice
The negotiator first finds all users who have submitted jobs and calculates their priority. Then, it totals the SlotWeight (by default, cores) of all currently available slots, and using the ratios of the user priorities, it calculates the number of cores each user could get. This is their pie slice. (See: SLOT_WEIGHT in Startd Daemon Configuration Options)
If any users have a floor defined via condor_userprio -set-floor , and their current allocation of cores is below the floor, a special round of the below-floor users goes first, attempting to allocate up to the defined number of cores for their floor level. These users are negotiated for in user priority order. This allows an admin to give users some “guaranteed” minimum number of cores, no matter what their previous usage or priority is.
After the below-floor users are negotiated for, all users are negotiated for, in user priority order. The condor_negotiator contacts each schedd where the user’s job lives, and asks for job information. The condor_schedd daemon (on behalf of a user) tells the matchmaker about a job, and the matchmaker looks at available slots to create a list that match the requirements expression. It then sorts the matching slots by the rank expressions within ClassAds. If a slot prefers a job via the slot RANK expression, the job is assigned to that slot, potentially preempting an already running job. Otherwise, give the slot to the job that the job ranks highest. If the highest ranked slot is already running a job, the negotiator may preempt the running job for the new job.
This matchmaking cycle continues until the user has received all of the slots for their pie slice. If there is a per-user ceiling defined with the condor_userprio -setceil command, and this ceiling is smaller than the pie slice, the user gets only up to their ceiling number of cores. The matchmaker then contacts the next highest priority user and offers that user their pie slice worth of slots. After contacting all users, the cycle is repeated with any still available slots and recomputed pie slices. The matchmaker continues spinning the pie until it runs out of slots or all the condor_schedd daemons say they have no more jobs.
Group Accounting
By default, HTCondor does all accounting on a per-user basis. This means that HTCondor keeps track of the historical usage per-user, calculates a priority and fair-share per user, and allows the administrator to change this fair-share per user. In HTCondor terminology, the accounting principal is called the submitter.
The name of this submitter is, by default, the name the schedd authenticated when the job was first submitted to the schedd. Usually, this is the operating system username. However, the submitter can override the username selected by setting the submit file option
accounting_group_user = ishmael
This means this job should be treated, for accounting purposes only, as “ishamel”, but “ishmael” will not be the operating system id the shadow or job uses. Note that HTCondor trusts the user to set this to a valid value. The administrator can use schedd requirements or transforms to validate such settings, if desired. accounting_group_user is frequently used in web portals, where one trusted operating system process submits jobs on behalf of different users.
Note that if many people submit jobs with identical accounting_group_user values, HTCondor treats them as one set of jobs for accounting purposes. So, if Alice submits 100 jobs as accounting_group_user ishmael, and so does Bob a moment later, HTCondor will not try to fair-share between them, as it would do if they had not set accounting_group_user. If all these jobs have identical requirements, they will be run First-In, First-Out, so whoever submitted first makes the subsequent jobs wait until the last one of the first submit is finished.
Accounting Groups with Hierarchical Group Quotas
With additional configuration, it is possible to create accounting groups, where the submitters within the group maintain their distinct identity, and fair-share still happens within members of that group.
An upper limit on the number of slots allocated to a group of users can be specified with group quotas.
Consider an example pool with thirty slots: twenty slots are owned by the physics group and ten are owned by the chemistry group. The desired policy is that no more than twenty concurrent jobs are ever running from the physicists, and only ten from the chemists. These slots are otherwise identical, so it does not matter which slots run which group’s jobs. It only matters that the proportions of allocated slots are correct.
Group quotas may implement this policy. Define the groups and set their quotas in the configuration of the central manager:
GROUP_NAMES = group_physics, group_chemistry
GROUP_QUOTA_group_physics = 20
GROUP_QUOTA_group_chemistry = 10
The implementation of quotas is hierarchical, such that quotas may be
described for the tree of groups, subgroups, sub subgroups, etc. Group
names identify the groups, such that the configuration can define the
quotas in terms of limiting the number of cores allocated for a group or
subgroup. Group names do not need to begin with "group_", but that
is the convention, which helps to avoid naming conflicts between groups
and subgroups. The hierarchy is identified by using the period (‘.’)
character to separate a group name from a subgroup name from a sub
subgroup name, etc. Group names are case-insensitive for negotiation.
At the root of the tree that defines the hierarchical groups is the “<none>” group. The implied quota of the “<none>” group will be all available slots. This string will appear in the output of condor_status.
If the sum of the child quotas exceeds the parent, then the child quotas
are scaled down in proportion to their relative sizes. For the given
example, there were 30 original slots at the root of the tree. If a
power failure removed half of the original 30, leaving fifteen slots,
physics would be scaled back to a quota of ten, and chemistry to five.
This scaling can be disabled by setting the condor_negotiator
configuration variable
NEGOTIATOR_ALLOW_QUOTA_OVERSUBSCRIPTION to True. If
the sum of the child quotas is less than that of the parent, the child
quotas remain intact; they are not scaled up. That is, if somehow the
number of slots doubled from thirty to sixty, physics would still be
limited to 20 slots, and chemistry would be limited to 10. This example
in which the quota is defined by absolute values is called a static
quota.
Each job must state which group it belongs to. By default, this is opt-in, and the system trusts each user to put the correct group in the submit description file. See “Setting Accounting Groups Automatically below” to configure the system to set them without user input and to prevent users from opting into the wrong groups. Jobs that do not identify themselves as a group member are negotiated for as part of the “<none>” group. Note that this requirement is per job, not per user. A given user may be a member of many groups. Jobs identify which group they are in by setting the accounting_group and accounting_group_user commands within the submit description file, as specified in the Group Accounting section. For example:
accounting_group = group_physics
accounting_group_user = einstein
The size of the quotas may instead be expressed as a proportion. This is then referred to as a dynamic group quota, because the size of the quota is dynamically recalculated every negotiation cycle, based on the total available size of the pool. Instead of using static quotas, this example can be recast using dynamic quotas, with one-third of the pool allocated to chemistry and two-thirds to physics. The quotas maintain this ratio even as the size of the pool changes, perhaps because of machine failures, because of the arrival of new machines within the pool, or because of other reasons. The job submit description files remain the same. Configuration on the central manager becomes:
GROUP_NAMES = group_physics, group_chemistry
GROUP_QUOTA_DYNAMIC_group_chemistry = 0.33
GROUP_QUOTA_DYNAMIC_group_physics = 0.66
The values of the quotas must be less than 1.0, indicating fractions of the pool’s machines. As with static quota specification, if the sum of the children exceeds one, they are scaled down proportionally so that their sum does equal 1.0. If their sum is less than one, they are not changed.
Extending this example to incorporate subgroups, assume that the physics group consists of high-energy (hep) and low-energy (lep) subgroups. The high-energy sub-group owns fifteen of the twenty physics slots, and the low-energy group owns the remainder. Groups are distinguished from subgroups by an intervening period character (.) in the group’s name. Static quotas for these subgroups extend the example configuration:
GROUP_NAMES = group_physics, group_physics.hep, group_physics.lep, group_chemistry
GROUP_QUOTA_group_physics = 20
GROUP_QUOTA_group_physics.hep = 15
GROUP_QUOTA_group_physics.lep = 5
GROUP_QUOTA_group_chemistry = 10
This hierarchy may be more useful when dynamic quotas are used. Here is the example, using dynamic quotas:
GROUP_NAMES = group_physics, group_physics.hep, group_physics.lep, group_chemistry
GROUP_QUOTA_DYNAMIC_group_chemistry = 0.33334
GROUP_QUOTA_DYNAMIC_group_physics = 0.66667
GROUP_QUOTA_DYNAMIC_group_physics.hep = 0.75
GROUP_QUOTA_DYNAMIC_group_physics.lep = 0.25
The fraction of a subgroup’s quota is expressed with respect to its parent group’s quota. That is, the high-energy physics subgroup is allocated 75% of the 66% that physics gets of the entire pool, however many that might be. If there are 30 machines in the pool, that would be the same 15 machines as specified in the static quota example.
High-energy physics users indicate which group their jobs should go in with the submit description file identification:
accounting_group = group_physics.hep
accounting_group_user = higgs
In all these examples so far, the hierarchy is merely a notational convenience. Each of the examples could be implemented with a flat structure, although it might be more confusing for the administrator. Surplus is the concept that creates a true hierarchy.
If a given group or sub-group accepts surplus, then that given group is
allowed to exceed its configured quota, by using the leftover, unused
quota of other groups. Surplus is disabled for all groups by default.
Accepting surplus may be enabled for all groups by setting
GROUP_ACCEPT_SURPLUS to
True. Surplus may be enabled for individual groups by setting
GROUP_ACCEPT_SURPLUS_<groupname> to True. Consider
the following example:
GROUP_NAMES = group_physics, group_physics.hep, group_physics.lep, group_chemistry
GROUP_QUOTA_group_physics = 20
GROUP_QUOTA_group_physics.hep = 15
GROUP_QUOTA_group_physics.lep = 5
GROUP_QUOTA_group_chemistry = 10
GROUP_ACCEPT_SURPLUS = false
GROUP_ACCEPT_SURPLUS_group_physics = false
GROUP_ACCEPT_SURPLUS_group_physics.lep = true
GROUP_ACCEPT_SURPLUS_group_physics.hep = true
This configuration is the same as above for the chemistry users.
However, GROUP_ACCEPT_SURPLUS is set to False globally,
False for the physics parent group, and True for the subgroups
group_physics.lep and group_physics.lep. This means that
group_physics.lep and group_physics.hep are allowed to exceed their
quota of 15 and 5, but their sum cannot exceed 20, for that is their
parent’s quota. If the group_physics had GROUP_ACCEPT_SURPLUS set
to True, then either group_physics.lep and group_physics.hep would
not be limited by quota.
Surplus slots are distributed bottom-up from within the quota tree. That is, any leaf nodes of this tree with excess quota will share it with any peers which accept surplus. Any subsequent excess will then be passed up to the parent node and over to all of its children, recursively. Any node that does not accept surplus implements a hard cap on the number of slots that the sum of it’s children use.
After the condor_negotiator calculates the quota assigned to each group, possibly adding in surplus, it then negotiates with the condor_schedd daemons in the system to try to match jobs to each group. It does this one group at a time. By default, it goes in “starvation group order.” That is, the group whose current usage is the smallest fraction of its quota goes first, then the next, and so on. The “<none>” group implicitly at the root of the tree goes last. This ordering can be replaced by defining configuration variable GROUP_SORT_EXPR. The condor_negotiator evaluates this ClassAd expression for each group ClassAd, sorts the groups by the floating point result, and then negotiates with the smallest positive value going first. Available attributes for sorting with GROUP_SORT_EXPR include:
Attribute Name |
Description |
|---|---|
AccountingGroup |
A string containing the group name |
GroupQuota |
The computed limit for this group |
GroupResourcesInUse |
The total slot weight used by this group |
GroupResourcesAllocated |
Quota allocated this cycle |
Table 3.3: Attributes visible to GROUP_SORT_EXPR
One possible group quota policy is strict priority. For example, a site
prefers physics users to match as many slots as they can, and only when
all the physics jobs are running, and idle slots remain, are chemistry
jobs allowed to run. The default “starvation group order” can be used to
implement this. By setting configuration variable
NEGOTIATOR_ALLOW_QUOTA_OVERSUBSCRIPTION to True, and
setting the physics quota to a number so large that it cannot ever be
met, such as one million, the physics group will always be the “most
starving” group, will always negotiate first, and will always be unable
to meet the quota. Only when all the physics jobs are running will the
chemistry jobs then run. If the chemistry quota is set to a value
smaller than physics, but still larger than the pool, this policy can
support a third, even lower priority group, and so on.
The condor_userprio command can show the current quotas in effect, and the current usage by group. For example:
$ condor_userprio -quotas
Last Priority Update: 11/12 15:18
Group Effective Config Use Subtree Requested
Name Quota Quota Surplus Quota Resources
------------------------ --------- --------- ------- --------- ----------
group_physics.hep 15.00 15.00 no 15.00 60
group_physics.lep 5.00 5.00 no 5.00 60
------------------------ --------- --------- ------- --------- ----------
Number of users: 2 ByQuota
This shows that there are two groups, each with 60 jobs in the queue. group_physics.hep has a quota of 15 cores, and group_physics.lep has 5 cores. Other options to condor_userprio, such as -most will also show the number of cores in use.
Setting Accounting Group automatically per user
By default, any user can put the jobs into any accounting group by setting parameters in the submit file. This can be useful if a person is a member of multiple groups. However, many sites want to force all jobs submitted by a given user into one accounting group, and forbid the user to submit to any other group. An HTCondor metaknob makes this easy. By adding to the access point’s configuration, the setting
USE Feature: AssignAccountingGroup(file_name_of_map)
The admin can create a file that maps the users into their required
accounting groups, and makes the attributes immutable, so they can’t
be changed. The format of this map file is like other classad map
files: Lines of three columns. The first should be an asterisk
*. The second column is the name of the user, and the final is the
accounting group that user should always submit to. For example,
* Alice group_physics
* Bob group_atlas
* Carol group_physics
* /^student_.*/ group_students
The second field can be a regular expression, if
enclosed in //. Note that this is on the submit side, and the
administrator will still need to create these group names and give them
a quota on the central manager machine. This file is re-read on a
condor_reconfig. The third field can also be a comma-separated list.
If so, it represents the set of valid accounting groups a user can
opt into. If the user does not set an accounting group in the submit file
the first entry in the list will be used.
Concurrency Limits
Concurrency limits allow an administrator to limit the number of concurrently running jobs that declare that they use some pool-wide resource. This limit is applied globally to all jobs submitted from all schedulers across one HTCondor pool; the limits are not applied to scheduler, local, or grid universe jobs. This is useful in the case of a shared resource, such as an NFS or database server that some jobs use, where the administrator needs to limit the number of jobs accessing the server.
The administrator must predefine the names and capacities of the resources to be limited in the negotiator’s configuration file. The job submitter must declare in the submit description file which resources the job consumes.
The administrator chooses a name for the limit. Concurrency limit names are case-insensitive. The names are formed from the alphabet letters ‘A’ to ‘Z’ and ‘a’ to ‘z’, the numerical digits 0 to 9, the underscore character ‘_’ , and at most one period character. The names cannot start with a numerical digit.
For example, assume that there are 3 licenses for the X software, so HTCondor should constrain the number of running jobs which need the X software to 3. The administrator picks XSW as the name of the resource and sets the configuration
XSW_LIMIT = 3
where XSW is the invented name of this resource, and this name is
appended with the string _LIMIT. With this limit, a maximum of 3
jobs declaring that they need this resource may be executed
concurrently.
In addition to named limits, such as in the example named limit XSW,
configuration may specify a concurrency limit for all resources that are
not covered by specifically-named limits. The configuration variable
CONCURRENCY_LIMIT_DEFAULT sets this value. For example,
CONCURRENCY_LIMIT_DEFAULT = 1
will enforce a limit of at most 1 running job that declares a usage of an unnamed resource. If CONCURRENCY_LIMIT_DEFAULT is omitted from the configuration, then no limits are placed on the number of concurrently executing jobs for which there is no specifically-named concurrency limit.
The job must declare its need for a resource by placing a command in its submit description file or adding an attribute to the job ClassAd. In the submit description file, an example job that requires the X software adds:
concurrency_limits = XSW
This results in the job ClassAd attribute
ConcurrencyLimits = "XSW"
Jobs may declare that they need more than one type of resource. In this case, specify a comma-separated list of resources:
concurrency_limits = XSW, DATABASE, FILESERVER
The units of these limits are arbitrary. This job consumes one unit of each resource. Jobs can declare that they use more than one unit with syntax that follows the resource name by a colon character and the integer number of resources. For example, if the above job uses three units of the file server resource, it is declared with
concurrency_limits = XSW, DATABASE, FILESERVER:3
If there are sets of resources which have the same capacity for each
member of the set, the configuration may become tedious, as it defines
each member of the set individually. A shortcut defines a name for a
set. For example, define the sets called LARGE and SMALL:
CONCURRENCY_LIMIT_DEFAULT = 5
CONCURRENCY_LIMIT_DEFAULT_LARGE = 100
CONCURRENCY_LIMIT_DEFAULT_SMALL = 25
To use the set name in a concurrency limit, the syntax follows the set
name with a period and then the set member’s name. Continuing this
example, there may be a concurrency limit named LARGE.SWLICENSE,
which gets the capacity of the default defined for the LARGE set,
which is 100. A concurrency limit named LARGE.DBSESSION will also
have a limit of 100. A concurrency limit named OTHER.LICENSE will
receive the default limit of 5, as there is no set named OTHER.
A concurrency limit may be evaluated against the attributes of a matched
machine. This allows a job to vary what concurrency limits it requires
based on the machine to which it is matched. To implement this, the job
uses submit command concurrency_limits_expr
instead of concurrency_limits
Consider an example in which execute machines are located on one of two
local networks. The administrator sets a concurrency limit to limit the
number of network intensive jobs on each network to 10. Configuration of
each execute machine advertises which local network it is on. A machine
on "NETWORK_A" configures
NETWORK = "NETWORK_A"
STARTD_ATTRS = $(STARTD_ATTRS) NETWORK
and a machine on "NETWORK_B" configures
NETWORK = "NETWORK_B"
STARTD_ATTRS = $(STARTD_ATTRS) NETWORK
The configuration for the negotiator sets the concurrency limits:
NETWORK_A_LIMIT = 10
NETWORK_B_LIMIT = 10
Each network intensive job identifies itself by specifying the limit within the submit description file:
concurrency_limits_expr = TARGET.NETWORK
The concurrency limit is applied based on the network of the matched machine.
An extension of this example applies two concurrency limits. One limit
is the same as in the example, such that it is based on an attribute of
the matched machine. The other limit is of a specialized application
called "SWX" in this example. The negotiator configuration is
extended to also include
SWX_LIMIT = 15
The network intensive job that also uses two units of the SWX
application identifies the needed resources in the single submit
command:
concurrency_limits_expr = strcat("SWX:2 ", TARGET.NETWORK)
Submit command concurrency_limits_expr may not be used together with submit command concurrency_limits.
Note that it is possible, under unusual circumstances, for more jobs to be started than should be allowed by the concurrency limits feature. In the presence of preemption and dropped updates from the condor_startd daemon to the condor_collector daemon, it is possible for the limit to be exceeded. If the limits are exceeded, HTCondor will not kill any job to reduce the number of running jobs to meet the limit.
Running Multiple Negotiators in One Pool
Usually, a single HTCondor pool will have a single condor_collector instance running and a single condor_negotiator instance running. However, there are special situation where you may want to run more than one condor_negotiator against a condor_collector, and still consider it one pool.
In such a scenario, each condor_negotiator is responsible for some non-overlapping partition of the slots in the pool. This might be for performance – if you have more than 100,000 slots in the pool, you may need to shard this pool into several smaller sections in order to lower the time each negotiator spends. Because accounting is done at the negotiator level, you may want to do this to have separate accounting and distinct fair share between different kinds of machines in your pool. For example, let’s say you have some GPU machines and non-GPU machines, and you want usage of the non-GPU machine to not “count” against the fair-share usage of GPU machines. One way to do this would be to have a separate negotiator for the GPU machines vs the non-GPU machines. At UW-Madison, we have a separate, small subset of our pool for quick-starting interactive jobs. By allocating a negotiator to only negotiate for these few machines, we can speed up the time to match these machines to interactive users who submit with condor_submit -i.
Sharding the negotiator is straightforward. Simply add the NEGOTIATOR entry to the DAEMON_LIST on an additional machine. While it is possible to run multiple negotiators on one machine, we may not want to, if we are trying to improve performance. Then, in each negotiator, set NEGOTIATOR_SLOT_CONSTRAINT to only match those slots this negotiator should use.
Running with multiple negotiators also means you need to be careful with the condor_userprio command. As there is no default negotiator, you should always name the specific negotiator you want to condor_userprio to talk to with the -name option.
Defragmenting Dynamic Slots
When partitionable slots are used, some attention must be given to the problem of the starvation of large jobs due to the fragmentation of slot. The problem is that over time the machine resources may become partitioned into slots suitable only for running small jobs. If a sufficient number of these slots do not happen to become idle at the same time on a machine, then a large job will not be able to claim that machine, even if the large job has a better priority than the small jobs.
One way of addressing the partitionable slot fragmentation problem is to periodically drain all jobs from fragmented machines so that they become defragmented. The condor_defrag daemon implements a configurable policy for doing that. Its implementation is targeted at machines configured to run whole-machine jobs and at machines that only have partitionable slots. The draining of a machine configured to have both partitionable slots and static slots would have a negative impact on single slot jobs running in static slots.
To use this daemon, DEFRAG must be added to DAEMON_LIST, and the
defragmentation policy must be configured. Typically, only one instance
of the condor_defrag daemon would be run per pool. It is a
lightweight daemon that should not require a lot of system resources.
Here is an example configuration that puts the condor_defrag daemon to work:
DAEMON_LIST = $(DAEMON_LIST) DEFRAG
DEFRAG_INTERVAL = 3600
DEFRAG_DRAINING_MACHINES_PER_HOUR = 1.0
DEFRAG_MAX_WHOLE_MACHINES = 20
DEFRAG_MAX_CONCURRENT_DRAINING = 10
This example policy tells condor_defrag to initiate draining jobs from 1 machine per hour, but to avoid initiating new draining if there are 20 completely defragmented machines or 10 machines in a draining state. A full description of each configuration variable used by the condor_defrag daemon may be found in the Defrag Daemon Configuration Options section.
By default, when a machine is drained, existing jobs are gracefully
evicted. This means that each job will be allowed to use the remaining
time promised to it by MaxJobRetirementTime. If the job has not
finished when the retirement time runs out, the job will be killed with
a soft kill signal, so that it has an opportunity to save a checkpoint
(if the job supports this).
By default, no new jobs will be allowed to start while the machine is draining. To reduce unused time on the machine caused by some jobs having longer retirement time than others, the eviction of jobs with shorter retirement time is delayed until the job with the longest retirement time needs to be evicted.
There is a trade off between reduced starvation and throughput. Frequent draining of machines reduces the chance of starvation of large jobs. However, frequent draining reduces total throughput. Some of the machine’s resources may go unused during draining, if some jobs finish before others. If jobs that cannot produce checkpoints are killed because they run past the end of their retirement time during draining, this also adds to the cost of draining.
To reduce these costs, you may set the configuration macro
DEFRAG_DRAINING_START_EXPR. If draining gracefully, the
defrag daemon will set the START expression for
the machine to this value expression. Do not set this to your usual
START expression; jobs accepted while draining will not be given
their MaxRetirementTime. Instead, when the last retiring job
finishes (either terminates or runs out of retirement time), all other
jobs on machine will be evicted with a retirement time of 0. (Those jobs
will be given their MaxVacateTime, as usual.) The machine’s
START expression will become FALSE and stay that way until - as
usual - the machine exits the draining state.
We recommend that you allow only interruptible jobs to start on draining
machines. Different pools may have different ways of denoting
interruptible, but a MaxJobRetirementTime of 0 is probably a good
sign. You may also want to restrict the interruptible jobs’
MaxVacateTime to ensure that the machine will complete draining
quickly.
To help gauge the costs of draining, the condor_startd advertises the
accumulated time that was unused due to draining and the time spent by
jobs that were killed due to draining. These are advertised respectively
in the attributes TotalMachineDrainingUnclaimedTime and
TotalMachineDrainingBadput. The condor_defrag daemon averages
these values across the pool and advertises the result in its daemon
ClassAd in the attributes AvgDrainingBadput and
AvgDrainingUnclaimed. Details of all attributes published by the
condor_defrag daemon are described in the Defrag ClassAd Attributes section.
The following command may be used to view the condor_defrag daemon ClassAd:
$ condor_status -l -any -constraint 'MyType == "Defrag"'
Configuring The HTCondorView Server
The HTCondorView server is an alternate use of the condor_collector that logs information on disk, providing a persistent, historical database of pool state. This includes machine state, as well as the state of jobs submitted by users.
An existing condor_collector may act as the HTCondorView collector through configuration. This is the simplest situation, because the only change needed is to turn on the logging of historical information. The alternative of configuring a new condor_collector to act as the HTCondorView collector is slightly more complicated, while it offers the advantage that the same HTCondorView collector may be used for several pools as desired, to aggregate information into one place.
The following sections describe how to configure a machine to run a HTCondorView server and to configure a pool to send updates to it.
Configuring a Machine to be a HTCondorView Server
To configure the HTCondorView collector, a few configuration variables are added or modified for the condor_collector chosen to act as the HTCondorView collector. These configuration variables are described in Collector Daemon Configuration Options. Here are brief explanations of the entries that must be customized:
- POOL_HISTORY_DIR
The directory where historical data will be stored. This directory must be writable by whatever user the HTCondorView collector is running as (usually the user condor). There is a configurable limit to the maximum space required for all the files created by the HTCondorView server called (POOL_HISTORY_MAX_STORAGE).
NOTE: This directory should be separate and different from the
spoolorlogdirectories already set up for HTCondor. There are a few problems putting these files into either of those directories.- KEEP_POOL_HISTORY
A boolean value that determines if the HTCondorView collector should store the historical information. It is
Falseby default, and must be specified asTruein the local configuration file to enable data collection.
Once these settings are in place in the configuration file for the
HTCondorView server host, create the directory specified in
POOL_HISTORY_DIR and make it writable by the user the HTCondorView
collector is running as. This is the same user that owns the
CollectorLog file in the log directory. The user is usually
condor.
If using the existing condor_collector as the HTCondorView collector, no further configuration is needed. To run a different condor_collector to act as the HTCondorView collector, configure HTCondor to automatically start it.
If using a separate host for the HTCondorView collector, to start it, add the
value COLLECTOR to DAEMON_LIST, and restart HTCondor on that
host. To run the HTCondorView collector on the same host as another
condor_collector, ensure that the two condor_collector daemons use
different network ports. Here is an example configuration in which the main
condor_collector and the HTCondorView collector are started up by the same
condor_master daemon on the same machine. In this example, the HTCondorView
collector uses port 12345.
VIEW_SERVER = $(COLLECTOR)
VIEW_SERVER_ARGS = -f -p 12345
VIEW_SERVER_ENVIRONMENT = "_CONDOR_COLLECTOR_LOG=$(LOG)/ViewServerLog"
DAEMON_LIST = MASTER, NEGOTIATOR, COLLECTOR, VIEW_SERVER
For this change to take effect, restart the condor_master on this host. This may be accomplished with the condor_restart command, if the command is run with administrator access to the pool.
High Availability of the Central Manager
Interaction with Flocking
The HTCondor high availability mechanisms discussed in this section currently do not work well in configurations involving flocking. The individual problems listed below interact to make the situation worse. Because of these problems, we advise against the use of flocking to pools with high availability mechanisms enabled.
The condor_schedd has a hard configured list of condor_collector and condor_negotiator daemons, and does not query redundant collectors to get the current condor_negotiator, as it does when communicating with its local pool. As a result, if the default condor_negotiator fails, the condor_schedd does not learn of the failure, and thus, talk to the new condor_negotiator.
When the condor_negotiator is unable to communicate with a condor_collector, it utilizes the next condor_collector within the list. Unfortunately, it does not start over at the top of the list. When combined with the previous problem, a backup condor_negotiator will never get jobs from a flocked condor_schedd.
Introduction to High availability
The condor_negotiator and condor_collector daemons are the heart of the HTCondor matchmaking system. The availability of these daemons is critical to an HTCondor pool’s functionality. Both daemons usually run on the same machine, most often known as the central manager. The failure of a central manager machine prevents HTCondor from matching new jobs and allocating new slots. High availability of the condor_negotiator and condor_collector daemons eliminates this problem.
Configuration allows one of multiple machines within the pool to function as the central manager. While there are may be many active condor_collector daemons, only a single, active condor_negotiator daemon will be running. The machine with the condor_negotiator daemon running is the active central manager. The other potential central managers each have a condor_collector daemon running; these are the idle central managers.
All submit and execute machines are configured to report to all potential central manager machines.
Each potential central manager machine runs the high availability daemon, condor_had. These daemons communicate with each other, constantly monitoring the pool to ensure that one active central manager is available. If the active central manager machine crashes or is shut down, these daemons detect the failure, and they agree on which of the idle central managers is to become the active one. A protocol determines this.
In the case of a network partition, idle condor_had daemons within each partition detect (by the lack of communication) a partitioning, and then use the protocol to chose an active central manager. As long as the partition remains, and there exists an idle central manager within the partition, there will be one active central manager within each partition. When the network is repaired, the protocol returns to having one central manager.
Through configuration, a specific central manager machine may act as the primary central manager. While this machine is up and running, it functions as the central manager. After a failure of this primary central manager, another idle central manager becomes the active one. When the primary recovers, it again becomes the central manager. This is a recommended configuration, if one of the central managers is a reliable machine, which is expected to have very short periods of instability. An alternative configuration allows the promoted active central manager (in the case that the central manager fails) to stay active after the failed central manager machine returns.
This high availability mechanism operates by monitoring communication between machines. Note that there is a significant difference in communications between machines when
a machine is down
a specific daemon (the condor_had daemon in this case) is not running, yet the machine is functioning
The high availability mechanism distinguishes between these two, and it operates based only on first (when a central manager machine is down). A lack of executing daemons does not cause the protocol to choose or use a new active central manager.
The central manager machine contains state information, and this includes information about user priorities. The information is kept in a single file, and is used by the central manager machine. Should the primary central manager fail, a pool with high availability enabled would lose this information (and continue operation, but with re-initialized priorities). Therefore, the condor_replication daemon exists to replicate this file on all potential central manager machines. This daemon promulgates the file in a way that is safe from error, and more secure than dependence on a shared file system copy.
The condor_replication daemon runs on each potential central manager machine as well as on the active central manager machine. There is a unidirectional communication between the condor_had daemon and the condor_replication daemon on each machine. To properly do its job, the condor_replication daemon must transfer state files. When it needs to transfer a file, the condor_replication daemons at both the sending and receiving ends of the transfer invoke the condor_transferer daemon. These short lived daemons do the task of file transfer and then exit. Do not place TRANSFERER into DAEMON_LIST, as it is not a daemon that the condor_master should invoke or watch over.
Configuration
The high availability of central manager machines is enabled through configuration. It is disabled by default. All machines in a pool must be configured appropriately in order to make the high availability mechanism work. See the High Availability Configuration Options section, for definitions of these configuration variables.
The condor_had and condor_replication daemons use the
condor_shared_port daemon by default. If you want to use more than
one condor_had or condor_replication daemon with the
condor_shared_port daemon under the same master, you must configure
those additional daemons to use nondefault socket names. (Set the
-sock option in <NAME>_ARGS.) Because the condor_had daemon
must know the condor_replication daemon’s address a priori, you will
also need to set <NAME>.REPLICATION_SOCKET_NAME appropriately.
The stabilization period is the time it takes for the condor_had daemons to detect a change in the pool state such as an active central manager failure or network partition, and recover from this change. It may be computed using the following formula:
Stabilization Period = 12 * (number of central managers) * $(HAD_CONNECTION_TIMEOUT)
To disable the high availability of central managers mechanism, it is sufficient to remove HAD, REPLICATION, and NEGOTIATOR from the DAEMON_LIST configuration variable on all machines, leaving only one condor_negotiator in the pool.
To shut down a currently operating high availability mechanism, follow the given steps. All commands must be invoked from a host which has administrative permissions on all central managers. The first three commands kill all condor_had, condor_replication, and all running condor_negotiator daemons. The last command is invoked on the host where the single condor_negotiator daemon is to run.
# condor_off -all -neg
# condor_off -all -subsystem -replication
# condor_off -all -subsystem -had
# condor_on -neg
When configuring condor_had to control the condor_negotiator, if the default backoff constant value is too small, it can result in a churning of the condor_negotiator, especially in cases in which the primary negotiator is unable to run due to misconfiguration. In these cases, the condor_master will kill the condor_had after the condor_negotiator exists, wait a short period, then restart condor_had. The condor_had will then win the election, so the secondary condor_negotiator will be killed, and the primary will be restarted, only to exit again. If this happens too quickly, neither condor_negotiator will run long enough to complete a negotiation cycle, resulting in no jobs getting started. Increasing this value via MASTER_HAD_BACKOFF_CONSTANT to be larger than a typical negotiation cycle can help solve this problem.
To run a high availability pool without the replication feature, do the following operations:
Set the HAD_USE_REPLICATION configuration variable to
False, and thus disable the replication on configuration level.Remove REPLICATION from both DAEMON_LIST and DC_DAEMON_LIST in the configuration file.
Sample Configuration
This section provides sample configurations for high availability.
We begin with a sample configuration using shared port, and then include a sample configuration for not using shared port. Both samples relate to the high availability of central managers.
Each sample is split into two parts: the configuration for the central manager machines, and the configuration for the machines that will not be central managers.
The following shared-port configuration is for the central manager machines.
## THE FOLLOWING MUST BE IDENTICAL ON ALL CENTRAL MANAGERS
CENTRAL_MANAGER1 = cm1.domain.name
CENTRAL_MANAGER2 = cm2.domain.name
CONDOR_HOST = $(CENTRAL_MANAGER1), $(CENTRAL_MANAGER2)
# Since we're using shared port, we set the port number to the shared
# port daemon's port number. NOTE: this assumes that each machine in
# the list is using the same port number for shared port. While this
# will be true by default, if you've changed it in configuration any-
# where, you need to reflect that change here.
HAD_USE_SHARED_PORT = TRUE
HAD_LIST = \
$(CENTRAL_MANAGER1):$(SHARED_PORT_PORT), \
$(CENTRAL_MANAGER2):$(SHARED_PORT_PORT)
REPLICATION_USE_SHARED_PORT = TRUE
REPLICATION_LIST = \
$(CENTRAL_MANAGER1):$(SHARED_PORT_PORT), \
$(CENTRAL_MANAGER2):$(SHARED_PORT_PORT)
# The recommended setting.
HAD_USE_PRIMARY = TRUE
# If you change which daemon(s) you're making highly-available, you must
# change both of these values.
HAD_CONTROLLEE = NEGOTIATOR
MASTER_NEGOTIATOR_CONTROLLER = HAD
## THE FOLLOWING MAY DIFFER BETWEEN CENTRAL MANAGERS
# The daemon list may contain additional entries.
DAEMON_LIST = MASTER, COLLECTOR, NEGOTIATOR, HAD, REPLICATION
# Using replication is optional.
HAD_USE_REPLICATION = TRUE
# This is the default location for the state file.
STATE_FILE = $(SPOOL)/Accountantnew.log
# See note above the length of the negotiation cycle.
MASTER_HAD_BACKOFF_CONSTANT = 360
The following shared-port configuration is for the machines which that will not be central managers.
CENTRAL_MANAGER1 = cm1.domain.name
CENTRAL_MANAGER2 = cm2.domain.name
CONDOR_HOST = $(CENTRAL_MANAGER1), $(CENTRAL_MANAGER2)
The following configuration sets fixed port numbers for the central manager machines.
##########################################################################
# A sample configuration file for central managers, to enable the #
# the high availability mechanism. #
##########################################################################
#########################################################################
## THE FOLLOWING MUST BE IDENTICAL ON ALL POTENTIAL CENTRAL MANAGERS. #
#########################################################################
## For simplicity in writing other expressions, define a variable
## for each potential central manager in the pool.
## These are samples.
CENTRAL_MANAGER1 = cm1.domain.name
CENTRAL_MANAGER2 = cm2.domain.name
## A list of all potential central managers in the pool.
CONDOR_HOST = $(CENTRAL_MANAGER1),$(CENTRAL_MANAGER2)
## Define the port number on which the condor_had daemon will
## listen. The port must match the port number used
## for when defining HAD_LIST. This port number is
## arbitrary; make sure that there is no port number collision
## with other applications.
HAD_PORT = 51450
HAD_ARGS = -f -p $(HAD_PORT)
## The following macro defines the port number condor_replication will listen
## on this machine. This port should match the port number specified
## for that replication daemon in the REPLICATION_LIST
## Port number is arbitrary (make sure no collision with other applications)
## This is a sample port number
REPLICATION_PORT = 41450
REPLICATION_ARGS = -p $(REPLICATION_PORT)
## The following list must contain the same addresses in the same order
## as CONDOR_HOST. In addition, for each hostname, it should specify
## the port number of condor_had daemon running on that host.
## The first machine in the list will be the PRIMARY central manager
## machine, in case HAD_USE_PRIMARY is set to true.
HAD_LIST = \
$(CENTRAL_MANAGER1):$(HAD_PORT), \
$(CENTRAL_MANAGER2):$(HAD_PORT)
## The following list must contain the same addresses
## as HAD_LIST. In addition, for each hostname, it should specify
## the port number of condor_replication daemon running on that host.
## This parameter is mandatory and has no default value
REPLICATION_LIST = \
$(CENTRAL_MANAGER1):$(REPLICATION_PORT), \
$(CENTRAL_MANAGER2):$(REPLICATION_PORT)
## The following is the name of the daemon that the HAD controls.
## This must match the name of a daemon in the master's DAEMON_LIST.
## The default is NEGOTIATOR, but can be any daemon that the master
## controls.
HAD_CONTROLLEE = NEGOTIATOR
## HAD connection time.
## Recommended value is 2 if the central managers are on the same subnet.
## Recommended value is 5 if Condor security is enabled.
## Recommended value is 10 if the network is very slow, or
## to reduce the sensitivity of HA daemons to network failures.
HAD_CONNECTION_TIMEOUT = 2
##If true, the first central manager in HAD_LIST is a primary.
HAD_USE_PRIMARY = true
###################################################################
## THE PARAMETERS BELOW ARE ALLOWED TO BE DIFFERENT ON EACH #
## CENTRAL MANAGER #
## THESE ARE MASTER SPECIFIC PARAMETERS
###################################################################
## the master should start at least these four daemons
DAEMON_LIST = MASTER, COLLECTOR, NEGOTIATOR, HAD, REPLICATION
## Enables/disables the replication feature of HAD daemon
## Default: false
HAD_USE_REPLICATION = true
## Name of the file from the SPOOL directory that will be replicated
## Default: $(SPOOL)/Accountantnew.log
STATE_FILE = $(SPOOL)/Accountantnew.log
## Period of time between two successive awakenings of the replication daemon
## Default: 300
REPLICATION_INTERVAL = 300
## Period of time, in which transferer daemons have to accomplish the
## downloading/uploading process
## Default: 300
MAX_TRANSFER_LIFETIME = 300
## Period of time between two successive sends of classads to the collector by HAD
## Default: 300
HAD_UPDATE_INTERVAL = 300
## The HAD controls the negotiator, and should have a larger
## backoff constant
MASTER_NEGOTIATOR_CONTROLLER = HAD
MASTER_HAD_BACKOFF_CONSTANT = 360
The configuration for machines that will not be central managers is identical for the fixed- and shared- port cases.
##########################################################################
# Sample configuration relating to high availability for machines #
# that DO NOT run the condor_had daemon. #
##########################################################################
## For simplicity define a variable for each potential central manager
## in the pool.
CENTRAL_MANAGER1 = cm1.domain.name
CENTRAL_MANAGER2 = cm2.domain.name
## List of all potential central managers in the pool
CONDOR_HOST = $(CENTRAL_MANAGER1),$(CENTRAL_MANAGER2)
Monitoring with Ganglia, Elasticsearch, etc.
HTCondor keeps operational data about different aspects of the system in different places: The condor_collector stores current data about all the slots and all the daemons in the system. If absent ads are enabled, the condor_collector also stores information about slots that are no longer in the system, for a fixed amount of time. All this data may be queried with appropriate options to the condor_status command. The AP’s job history file stores data about recent completed and removed jobs, similarly, each EP stores a startd_history file with information about jobs that have only run on that EP. Both of these may be queried with the condor_history command.
While using condor_status or condor_history works well for one-off or ad-hoc queries, both tend to be slow, because none of the data is indexed or stored in a proper database. Furthermore, all these data sources age old data out quickly. Also, there is no graphical UI provided to visualize or analyze any of the data.
As there are many robust, well-documented systems to do these sorts of things, the best solution is to copy the original data out of the proprietary HTCondor formats and into third party monitoring, database and visualization systems.
The condor_gangliad is an HTCSS daemon that periodically copies data out of the condor_collector and into the ganglia monitoring system. It can also be used to populate grafana. condor_adstash is a HTCSS daemon which can copy job history information out of the AP’s history file and into the Elasticsearch database for further querying.
Ganglia
Installation and configuration of Ganglia itself is beyond the scope of this document: complete information is available at the ganglia homepage at (http://ganglia.info/), from the O’Reilly book on the subject, or numerous webpages.
Generally speaking, the condor_gangliad should be setup to run on the same system where the ganglia gmetad is running. Unless the pools is exceptionally large, putting the gmetad and the condor_gangliad on the central manager machine is a good choice. To enable the condor_gangliad, simply add the line
use FEATURE: ganglia
to the config file on the central manager machine, and condor_restart the HTCondor system on that machine. If the condor_gangliad daemon is to run on a different machine than the one running Ganglia’s gmetad, modify configuration variable GANGLIA_GSTAT_COMMAND to get the list of monitored hosts from the master gmond program.
The above steps alone should be sufficient to get a default set of metrics about the pool into ganglia. Additional metrics, tuning and other information, if needed, follows.
By default, the condor_gangliad will only propagate metrics to hosts that are
already monitored by Ganglia. Set configuration variable
GANGLIA_SEND_DATA_FOR_ALL_HOSTS to True to set up a Ganglia host
to monitor a pool not monitored by Ganglia or have a heterogeneous pool where
some hosts are not monitored. In this case, default graphs that Ganglia
provides will not be present. However, the HTCondor metrics will appear.
On large pools, setting configuration variable
GANGLIAD_PER_EXECUTE_NODE_METRICS to False will reduce the amount
of data sent to Ganglia. The execute node data is the least important to
monitor. One can also limit the amount of data by setting configuration
variable GANGLIAD_REQUIREMENTS Be aware that aggregate sums over the
entire pool will not be accurate if this variable limits the ClassAds queried.
Metrics to be sent to Ganglia are specified in files within the directory specified by variable GANGLIAD_METRICS_CONFIG_DIR. Here is an example of a single metric definition given as a New ClassAd:
[
Name = "JobsSubmitted";
Desc = "Number of jobs submitted";
Units = "jobs";
TargetType = "Scheduler";
]
A nice set of default metrics is in file:
$(GANGLIAD_METRICS_CONFIG_DIR)/00_default_metrics.
Recognized metric attribute names and their use:
- Name
The name of this metric, which corresponds to the ClassAd attribute name. Metrics published for the same machine must have unique names.
- Value
A ClassAd expression that produces the value when evaluated. The default value is the value in the daemon ClassAd of the attribute with the same name as this metric.
- Desc
A brief description of the metric. This string is displayed when the user holds the mouse over the Ganglia graph for the metric.
- Verbosity
The integer verbosity level of this metric. Metrics with a higher verbosity level than that specified by configuration variable GANGLIAD_VERBOSITY will not be published.
- TargetType
A string containing a comma-separated list of daemon ClassAd types that this metric monitors. The specified values should match the value of MyType of the daemon ClassAd. In addition, there are special values that may be included. “Machine_slot1” may be specified to monitor the machine ClassAd for slot 1 only. This is useful when monitoring machine-wide attributes. The special value “ANY” matches any type of ClassAd.
- Requirements
A boolean expression that may restrict how this metric is incorporated. It defaults to
True, which places no restrictions on the collection of this ClassAd metric.- Title
The graph title used for this metric. The default is the metric name.
- Group
A string specifying the name of this metric’s group. Metrics are arranged by group within a Ganglia web page. The default is determined by the daemon type. Metrics in different groups must have unique names.
- Cluster
A string specifying the cluster name for this metric. The default cluster name is taken from the configuration variable GANGLIAD_DEFAULT_CLUSTER.
- Units
A string describing the units of this metric.
- Scale
A scaling factor that is multiplied by the value of the
Valueattribute. The scale factor is used when the value is not in the basic unit or a human-interpretable unit. For example, duty cycle is commonly expressed as a percent, but the HTCondor value ranges from 0 to 1. So, duty cycle is scaled by 100. Some metrics are reported in KiB. Scaling by 1024 allows Ganglia to pick the appropriate units, such as number of bytes rather than number of KiB. When scaling by large values, converting to the “float” type is recommended.- Derivative
A boolean value that specifies if Ganglia should graph the derivative of this metric. If
True, and this metric is an aggregate metric, then the derivative of each value to be aggregated is computed, and the aggregate function is applied to these derivatives. This is useful for numeric attributes that are “counters”, i.e. they start at zero and are monotonically increasing throughout the lifetime of a slot or a daemon. For example, consider the schedd ad attribute FileTransferUploadBytes which publishes the total number of bytes uploaded by the schedd. IfDerivativeis set toTrue, and this metric is an aggregate metric, then the sum of the derivatives of “FileTransferUploadBytes” across the pool is computed and published. The derivative of “FileTransferUploadBytes” for each ClassAd is the positive change in the value of “FileTransferUploadBytes” since the last update. If this metric is not an aggregate metric, then computing of the derivative is performed by Ganglia as usual (note: this requires Ganglia versions 3.4 or later).- Type
A string specifying the type of the metric. Possible values are “double”, “float”, “int32”, “uint32”, “int16”, “uint16”, “int8”, “uint8”, and “string”. The default is “string” for string values, the default is “int32” for integer values, the default is “float” for real values, and the default is “int8” for boolean values. Integer values can be coerced to “float” or “double”. This is especially important for values stored internally as 64-bit values.
- Regex
This string value specifies a regular expression that matches attributes to be monitored by this metric. This is useful for dynamic attributes that cannot be enumerated in advance, because their names depend on dynamic information such as the users who are currently running jobs. When this is specified, one metric per matching attribute is created. The default metric name is the name of the matched attribute, and the default value is the value of that attribute. As usual, the
Valueexpression may be used when the raw attribute value needs to be manipulated before publication. However, since the name of the attribute is not known in advance, a special ClassAd attribute in the daemon ClassAd is provided to allow theValueexpression to refer to it. This special attribute is namedRegex. Another special feature is the ability to refer to text matched by regular expression groups defined by parentheses within the regular expression. These may be substituted into the values of other string attributes such asNameandDesc. This is done by putting macros in the string values. “\\1” is replaced by the first group, “\\2” by the second group, and so on.- Aggregate
This string value specifies an aggregation function to apply, instead of publishing individual metrics for each daemon ClassAd. Possible values are “sum”, “avg”, “max”, and “min”.
- AggregateGroup
When an aggregate function has been specified, this string value specifies which aggregation group the current daemon ClassAd belongs to. The default is the metric
Name. This feature works like GROUP BY in SQL. The aggregation function produces one result per value ofAggregateGroup. A single aggregate group would therefore be appropriate for a pool-wide metric. As an example, to publish the sum of an attribute across different types of slot ClassAds, make the metric name an expression that is unique to each type. The defaultAggregateGroupwould be set accordingly. Note that the assumption is still that the result is a pool-wide metric, so by default it is associated with the condor_collector daemon’s host. To group by machine and publish the result into the Ganglia page associated with each machine, make theAggregateGroupcontain the machine name and override the defaultMachineattribute to be the daemon’s machine name, rather than the condor_collector daemon’s machine name.- Machine
The name of the host associated with this metric. If configuration variable GANGLIAD_DEFAULT_MACHINE is not specified, the default is taken from the
Machineattribute of the daemon ClassAd. If the daemon name is of the form name@hostname, this may indicate that there are multiple instances of HTCondor running on the same machine. To avoid the metrics from these instances overwriting each other, the default machine name is set to the daemon name in this case. For aggregate metrics, the default value ofMachinewill be the name of the condor_collector host.- IP
A string containing the IP address of the host associated with this metric. If GANGLIAD_DEFAULT_IP is not specified, the default is extracted from the
MyAddressattribute of the daemon ClassAd. This value must be unique for each machine published to Ganglia. It need not be a valid IP address. If the value ofMachinecontains an “@” sign, the default IP value will be set to the same value asMachinein order to make the IP value unique to each instance of HTCondor running on the same host.- Lifetime
A positive integer value representing the max number of seconds without updating a metric will be kept before deletion. This is represented in ganglia as DMAX. If no Lifetime is defined for a metric then the default value will be set to a calculated value based on the ganglia publish interval with a minimum value set by GANGLIAD_MIN_METRIC_LIFETIME.
Absent ClassAds
By default, HTCondor assumes that slots are transient: the condor_collector will discard ClassAds older than CLASSAD_LIFETIME seconds. Its default configuration value is 15 minutes, and as such, the default value for UPDATE_INTERVAL will pass three times before HTCondor forgets about a resource. In some pools, especially those with dedicated resources, this approach may make it unnecessarily difficult to determine what the composition of the pool ought to be, in the sense of knowing which machines would be in the pool, if HTCondor were properly functioning on all of them.
This assumption of transient machines can be modified by the use of absent
ClassAds. When a slot ClassAd would otherwise expire, the condor_collector
evaluates the configuration variable ABSENT_REQUIREMENTS against the
machine ClassAd. If True, the machine ClassAd will be saved in a persistent
manner and be marked as absent; this causes the machine to appear in the output
of condor_status -absent. When the machine returns to the pool, its first
update to the condor_collector will invalidate the absent machine ClassAd.
Absent ClassAds, like offline ClassAds, are stored to disk to ensure that they are remembered, even across condor_collector crashes. The configuration variable COLLECTOR_PERSISTENT_AD_LOG defines the file in which the ClassAds are stored. Absent ClassAds are retained on disk as maintained by the condor_collector for a length of time in seconds defined by the configuration variable ABSENT_EXPIRE_ADS_AFTER. A value of 0 for this variable means that the ClassAds are never discarded, and the default value is thirty days.
Absent ClassAds are only returned by the condor_collector and displayed when the -absent option to condor_status is specified, or when the absent machine ClassAd attribute is mentioned on the condor_status command line. This renders absent ClassAds invisible to the rest of the HTCondor infrastructure.
A daemon may inform the condor_collector that the daemon’s ClassAd should not
expire, but should be removed right away; the daemon asks for its ClassAd to be
invalidated. It may be useful to place an invalidated ClassAd in the absent
state, instead of having it removed as an invalidated ClassAd. An example of a
ClassAd that could benefit from being absent is a system with an
uninterruptible power supply that shuts down cleanly but unexpectedly as a
result of a power outage. To cause all invalidated ClassAds to become absent
instead of invalidated, set EXPIRE_INVALIDATED_ADS to True.
Invalidated ClassAds will instead be treated as if they expired, including when
evaluating ABSENT_REQUIREMENTS.
Elasticsearch
HTCondor supports pushing condor_schedd and condor_startd job and job epoch ClassAds to Elasticsearch (and other targets) via the condor_adstash tool/daemon. condor_adstash collects job ClassAds as specified by its configuration, either querying specified daemons or reading job ClassAds from a specified file, converts each ClassAd to a JSON document, and pushes each doc to the configured Elasticsearch index. The index is automatically created if it does not exist, and fields are added and configured based on well known job ClassAd attributes. (Custom attributes are also pushed, though always as keyword fields.)
condor_adstash is a Python 3.6+ script that uses the HTCondor Python Bindings and the Python Elasticsearch Client, both of which must be available to the system Python 3 installation if using the daemonized version of condor_adstash. condor_adstash can also be run as a stand alone tool (e.g. in a Python 3 virtual environment containing the necessary libraries).
Running condor_adstash as a daemon (i.e. under the watch of the
condor_master) can be enabled by adding
use feature : adstash
to your HTCondor configuration.
By default, this configuration will poll the job history on all
condor_schedds that report to the $(CONDOR_HOST) condor_collector
every 20 minutes and push the contents of the job history ClassAds to an
Elasticsearch instance running on localhost to an index named
htcondor-000001.
Your situation and monitoring needs are likely different!
See the condor_config.local.adstash example configuration file in
the examples/ directory for detailed information on how to modify
your configuration.
If you prefer to run condor_adstash in standalone mode, or are curious about other ClassAd sources or targets, see the condor_adstash man page for more details.
Configuring a Pool to Report to the HTCondorView Server
For the HTCondorView server to function, configure the existing collector to forward ClassAd updates to it. This configuration is only necessary if the HTCondorView collector is a different collector from the existing condor_collector for the pool. All the HTCondor daemons in the pool send their ClassAd updates to the regular condor_collector, which in turn will forward them on to the HTCondorView server.
Define the following configuration variable:
CONDOR_VIEW_HOST = full.hostname[:portnumber]
where full.hostname is the full host name of the machine running the HTCondorView collector. The full host name is optionally followed by a colon and port number. This is only necessary if the HTCondorView collector is configured to use a port number other than the default.
Place this setting in the configuration file used by the existing condor_collector. It is acceptable to place it in the global configuration file. The HTCondorView collector will ignore this setting (as it should) as it notices that it is being asked to forward ClassAds to itself.
Once the HTCondorView server is running with this change, send a condor_reconfig command to the main condor_collector for the change to take effect, so it will begin forwarding updates. A query to the HTCondorView collector will verify that it is working. A query example:
$ condor_status -pool condor.view.host[:portnumber]
A condor_collector may also be configured to report to multiple HTCondorView servers. The configuration variable CONDOR_VIEW_HOST can be given as a list of HTCondorView servers separated by commas and/or spaces.
The following demonstrates an example configuration for two HTCondorView servers, where both HTCondorView servers (and the condor_collector) are running on the same machine, localhost.localdomain:
VIEWSERV01 = $(COLLECTOR)
VIEWSERV01_ARGS = -f -p 12345 -local-name VIEWSERV01
VIEWSERV01_ENVIRONMENT = "_CONDOR_COLLECTOR_LOG=$(LOG)/ViewServerLog01"
VIEWSERV01.POOL_HISTORY_DIR = $(LOCAL_DIR)/poolhist01
VIEWSERV01.KEEP_POOL_HISTORY = TRUE
VIEWSERV01.CONDOR_VIEW_HOST =
VIEWSERV02 = $(COLLECTOR)
VIEWSERV02_ARGS = -f -p 24680 -local-name VIEWSERV02
VIEWSERV02_ENVIRONMENT = "_CONDOR_COLLECTOR_LOG=$(LOG)/ViewServerLog02"
VIEWSERV02.POOL_HISTORY_DIR = $(LOCAL_DIR)/poolhist02
VIEWSERV02.KEEP_POOL_HISTORY = TRUE
VIEWSERV02.CONDOR_VIEW_HOST =
CONDOR_VIEW_HOST = localhost.localdomain:12345 localhost.localdomain:24680
DAEMON_LIST = $(DAEMON_LIST) VIEWSERV01 VIEWSERV02
Note that the value of CONDOR_VIEW_HOST for VIEWSERV01 and VIEWSERV02 is unset, to prevent them from inheriting the global value of CONDOR_VIEW_HOST and attempting to report to themselves or each other. If the HTCondorView servers are running on different machines where there is no global value for CONDOR_VIEW_HOST, this precaution is not required.
Scaling and Performance Considerations for the CM
The central manager (CM), as the central point of an HTCondor system, is designed to be scalable out of the box to large systems. As long as it is installed on dedicated, reasonable hardware, it should be able to manage a local pool of 100,000 cores. One reason for the scalability is that the CM is mostly stateless, meaning that it does not keep many records on disk. However, as some sites are scaling out beyond this size, there are some additional considerations and configurations to keep in mind.
Scaling up the Collector
For pools of the largest size, it may be necessary to set up a tree of collectors. This is described here: Recipe: Setting up a Collector Tree
Scaling up the Negotiator
The metric to measure the performance of the negotiator is the negotiator cycle time, which is the time it takes for the negotiator to complete one complete matchmaking cycle. In a healthy pool, this may take on the order of ten minutes. If the cycle is longer than that, consider sharding the negotiator as described above. To the first degree, the cycle time scales by the product of the number of autoclusters in all the condor_schedd and the number of idle slots. If you do not need preemption of running jobs in your system, setting the knob NEGOTIATOR_CONSIDER_PREEMPTION to false can dramatically speed up the negotiation cycle.